Determining optimal hardware specs for Klaytn node operators

Most blockchain platforms – including Klaytn – provide recommended hardware specifications for node operators. However, these recommendations are often designed to cater for broad use cases and may not be a perfect match for your specific needs, which could lead to unnecessary operating costs.
To help Klaytn node operators optimize their hardware specifications, we ran an experiment on a range of different hardware configurations and benchmarked their price and performance, which we detail further below in this post. Additionally, based on the benchmark results, we have also updated our recommended specifications for Klaytn nodes, to reflect advancements in CPU performance cloud pricing and the accumulation of data on the Klaytn mainnet over the past couple of years.
While the updated recommended specs will help to reduce node operating costs, we still strongly suggest node operators to determine your optimal hardware specifications by referencing the test results below.
Before we delve into the results, here is some necessary knowledge for blockchain node operation:
Storage
The higher the IOPS, the faster read and write speed is. However, if there is a lot of data accumulated in the blockchain, those values can dramatically affect the speed of block creation and block processing. This is because it may not be possible to store all DB values in the cache when dealing with large amounts of data. If the values cannot be stored in the cache DB, the data must be accessed from storage, which can become a performance bottleneck.
Memory
Memory size makes a big difference in performance, as the frequency and volume of I/O access is reduced , more data can be stored in memory. However, recklessly increasing the memory size is not always effective for the performance, as having excessive memory will not necessarily
decrease the miss rate.
Protip: Klaytn code provides a klaytn_trie_memcache_clean_miss cache miss indicator, which is useful for identifying the optimal amount of memory you need.
CPU
While parallel processing is important for a blockchain node to perform its various functions, such as managing transactions in a transaction pool or synchronizing blocks, single-core performance has the most significant impact on the overall node performance. This is because block processing, which is the most critical aspect, is single-threaded.
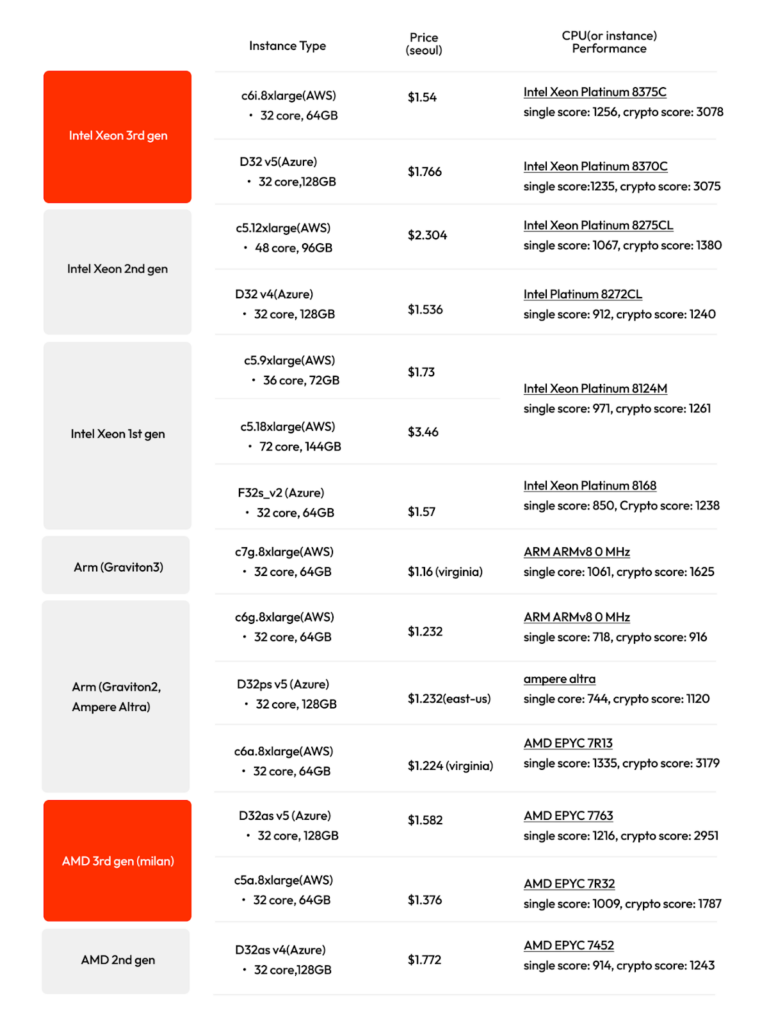
CPU benchmarks and prices
The table below contains the prices and benchmark results of the CPUs that the popular cloud services such as AWS and Azure provide.
For Intel and AMD CPUs, the crypto score of their latest generations have increased over two to three times compared to previous generations. The single scores which measure overall performance, have also increased by 20% to 30%.
However, if you look at the prices set by these cloud services, the difference between old and new generation isn’t as large. Therefore, it is currently more cost-effective to use the latest generation of CPUs.
The experiment and results
Before delving into the configuration of the experiment, we will first cover a brief explanation of the Klaytn network. There are three types of Klaytn nodes: EN (endpoint nodes), PN (proxy nodes), and CN (consensus nodes).
EN is used to accept and process the transactions, and its rpc port is usually open to the public. The transactions that need to be included in the block are then delivered to the PN connected through the bootnode. The PN receives the incoming transactions from the various ENs and delivers them to the CNs which are responsible for creating blocks.
The experiment was conducted on a private Klaytn network consisting of 4 CNs, 8 PNs, and 4 ENs, with the CN’s CPU / memory / storage specifications as the experiment’s variables. The goal of the experiment is to see which hardware configuration delivers the highest TPS, while also keeping an eye out for problems in terms of stability, such as out-of-memory (OOM).
The test load is as below:
- 6,000 RPS (request-per-second): Load the network by issuing 6,000 transactions per second. Each transaction sends KLAY from the sender to the receiver.
- 50 million test accounts, with 10% active: There are approximately 30 million EOAs on the Klaytn mainnet. Considering there will be more in the future, we have set the number of test accounts to 50 million. These accounts are filled with KLAY in advance, and through this, the size of the DB increases significantly by creating new accounts, and it decreases the DB read speed. When issuing the test transactions, only 10% of the test accounts are used in the actual test. This setting is based on the actual number of the active accounts.
For the experiment, we picked various types of AWS EC2 as CN instance types, loaded the network and recorded the TPS. The c5 type, which is an Intel Xeon 2nd gen, was included in the test as a reference.
Test 1
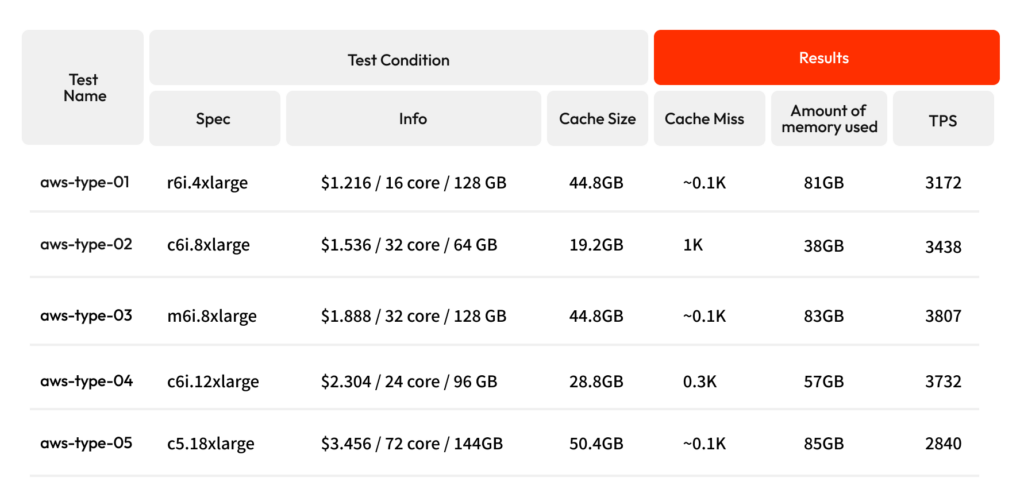
- Cache Size: This is the cache of the StateDB. It is a copy of the recently read and written state values. The cache is located at the memory for faster access than the DB. In Klaytn, 30~40% of the total physical memory size is allocated to cache by default, but this can be specified by the node operator through the –state.tries-in-memory flag.
- Cache miss: When there is no value to be read in the cache, it is said that a cache miss has occurred. In this case, the value has to be read from DB and it is slower than reading directly from the cache because it requires an I/O operation.
- Amount of memory used: This number recorded here reflects the stable amount of memory used by the node.
As seen by our experiment results, node operators should use at least m6i.8xlarge to reach 4,000 TPS. Other observations include:
- 0.1K can be considered the lowest cache miss rate, so the memory size should be at least 100 GB to achieve the lowest cache miss rate.
- When comparing the performance of nodes running on different AWS instance types, it is observed that the number of CPU cores has an impact on TPS (transactions per second), as evidenced by the results of aws-type-01 and aws-type-03 where the only difference is the CPU core count.
- However, we also found that the CPU performance is crucial, as shown by the low TPS on aws-type-05, despite having the highest memory and core count. This reinforces our above analysis that it is most efficient to choose the latest generation of CPUs.
Test 2
The following test is to see if OOM occurs while changing the cache size of the state db.
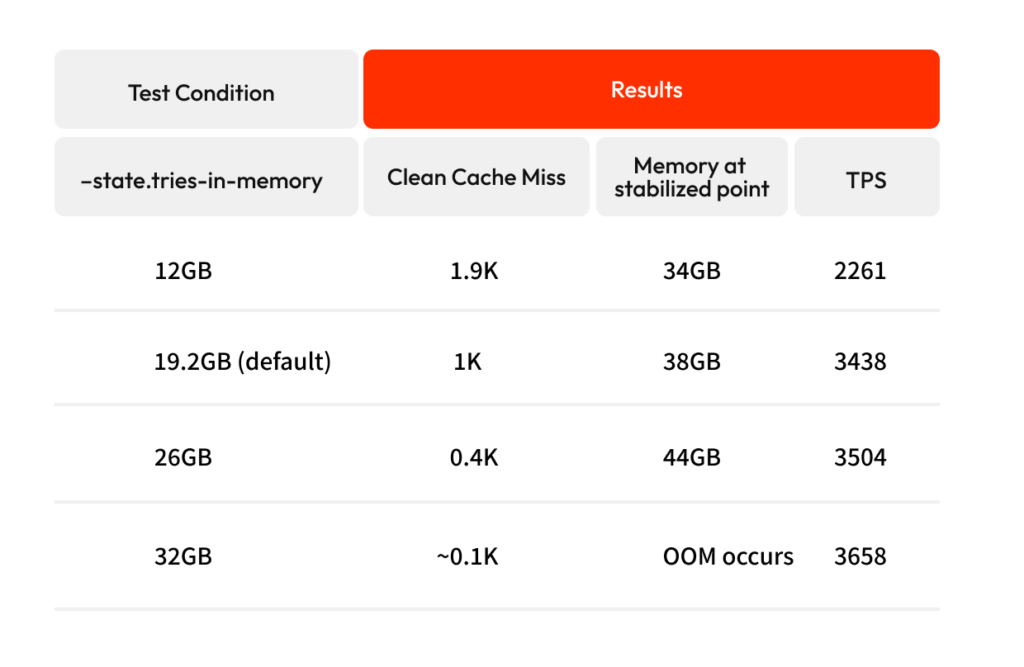
- EC2 used in this test: c6i.8xlarge(32 core, 64GB)
- Choose 64GB, the recommended memory size of EN
- Among them, c6i is picked which has the highest number of cores compared to memory size.
As the cache size continues to increase, the required memory size will eventually exceed the total physical memory, and OOM will occur. Therefore, at least 20 GB should be left as free space to prevent the OOM issue. Additionally, our storage tests also concluded that higher IOPS results in better performance.
Recommended specs
Based on our test results above, here are the updated recommended specs:
Recommend spec
- CN: aws – m6i.8xlarge, azure – D32s v5 (32 core or more, 100GB or more)
- PN: aws – m6i.4xlarge, azure – D16s v5 (16 core or more, 60GB or more)
- EN: aws – r6i.2xlarge, azure – E8 v5 (8 core or more, 60GB or more)
Storage
- Please set it as high as you can. Ex. gp3, 16000 iops, 500 MiB/s of throughput
Estimated operating costs for one year according to the specifications for each recommended cloud environment are as follows. Based on our estimates, these new recommended specs will lead to around 30% cost savings when running a CCO, compared to the old specs.
AWS, Seoul Region
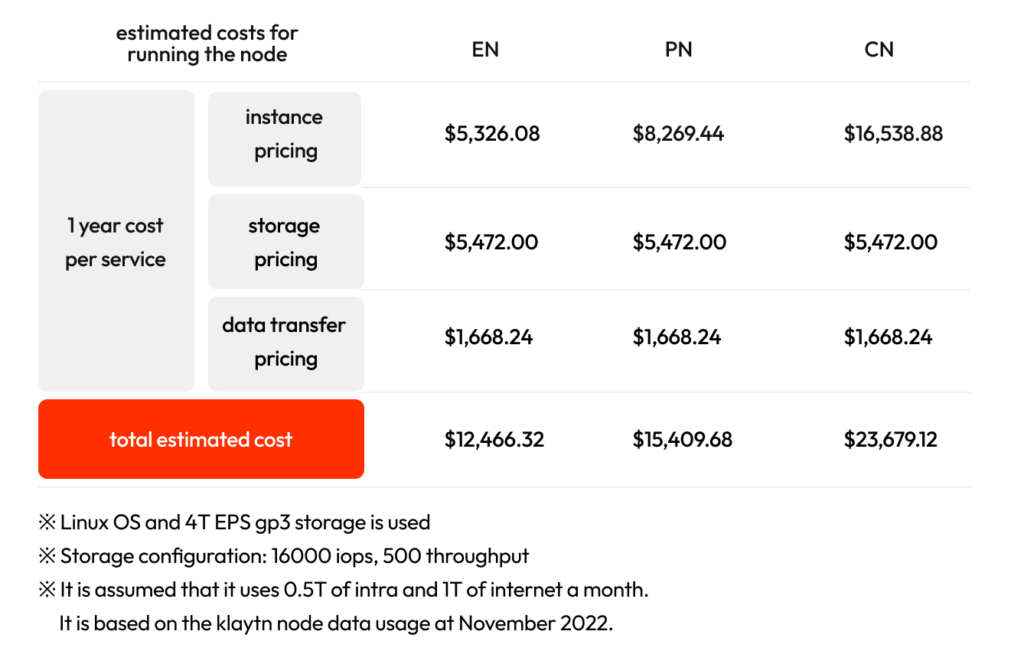
Azure, Korea Central Region

However, your savings can vary depending on how you use the node, so it is always better to determine your optimal node specifications based on your usage needs.
Recommended specs for specific situations
- In the case of CN/PN, a lot of memory is required to perform the state migration. As such, in cloud environments, it is recommended to increase memory when performing a migration. See https://docs.klaytn.foundation/content/operation-guide/chaindata-migration for more information.
- In the case of EN, higher CPU/memory may be required depending on the number of API requests or users connecting through the HTTP/WS server.
While operating costs can be difficult to optimize due to the complexity of operating blockchain nodes, this guide should provide you with a good starting point to work towards minimizing costs.