
Klaytn v1.11.0의 새로운 기능인 StateDB Live Pruning 기능을 소개합니다.
배경
블록체인의 데이터 중 가장 많은 용량을 차지하는 DB는 StateDB(계정 및 스토리지 trie)입니다. 현재의 StateDB는 노드의 값을 변경시키지 않고, 새로운 노드를 DB에 추가하는 방식으로 운영됩니다. 매 블록마다 변경되는 정보를 Merkle Patricia Trie(이하 MPT)로 관리 하기 때문에 1개의 정보가 바뀌어도 trie 중간 노드들의 정보도 변해서 6~10여개의 trie node가 변경됩니다. 이런 구조로 인해 StateDB는 시간이 지날 수록 엄청난 속도로 데이터 양이 증가하게 됩니다. 과거의 데이터를 삭제함으로써 블록체인 node를 경량화하려는 노력은 줄곧 있었으나 trie-node의 중복참조(multi reference) 문제 때문에 이전 데이터를 지우는 일(pruning)은 상당히 어렵습니다. 그래서 블록체인의 노드를 잠시 멈추고 마이그레이션해서 과거 데이터를 지우고 최신데이터로 StateDB를 가볍게 만든 후 다시 블록체인 노드로 참여하는 방식을 사용해 왔었습니다(StateDB Offline Pruning).
StateDB Live Pruning 소개
StateDB Live Pruning 기술은 블록체인의 state trie node의 hash 중복을 없애면서도 기존의 MPT hashRoot의 계산 결과는 동일하게 유지하여 state trie node의 다중 참조 문제를 해결합니다. 이로써 과거 데이터를 자유롭게 지우거나 다른 스토리지로 이동시켜 노드의 특성에 맞게 스토리지를 활용할 수 있게 됩니다. 이제 trie node 중복 참조 문제가 구체적으로 무엇이며 StateDB Live Pruning 기능이 어떻게 이 문제를 극복하여 Offline Pruning이 아닌 Live Pruning을 구현하는지 살펴보려고 합니다.
State Trie란?
Klaytn은 모든 account 정보를 트리 형태 자료 구조인 MPT에 저장합니다. 이 트리를 state trie라고도 하며 트리는 Klaytn node 스토리지에 저장됩니다. state trie는 Klaytn 블록체인의 모든 블록마다 존재합니다. 즉, Klaytn의 블록 1개에는 계좌들의 정보를 저장하는 state trie 1개가 있습니다. (출처 : Klaytn v1.5.0 State Migration: 노드 스토리지 절약하기 )
state trie에 관련한 좀더 자세한 설명은 다음 링크를 참고하십시오.
State Trie의 key 중복 사용 문제
일반적으로 블록체인의 state trie는 key-value로 저장되며, value안에서 다른 key를 참조하는 구조로 되어 있습니다. key는 value를 RLP 인코딩한 결과의 hash값이며, 일반적으로 길이는 32byte입니다. 이러한 이유로 동일한 value는 동일한 hash를 얻게 되고, key가 중복 사용 됩니다. key가 중복이면 동일한 value이므로 1개의 key만 스토리지에 저장되며, state trie안에서 중복 참조되어 데이터를 공유하는 방식으로 스토리지 공간을 아낄 수 있습니다.
하지만 1개의 key를 공유하므로 state trie 각 key의 참조 범위를 알 수 없어 state trie의 key는 삭제가 안되고 누적되기만 합니다. 또한 공유를 통해 절약할 수 있는 스토리지 공간도 2%정도에 불과합니다.
Exthash의 도입
State trie에서 key 중복 사용 문제를 해결하기 위해 Exthash(extended hash)라는 새로운 hash type을 생성하였습니다.
- 기존 hash : 32 byte Keccak256 hash
- Exthash : 32 byte Keccak256 hash + 7 byte serial index (nonce)
기존의 hash에 중복 문제를 없애고자 Exthash는 기존 hash에 7byte의 serial index (nonce)를 추가하였습니다. 앞의 hash값에 상관없이 value를 hash할 때마다 새로운 7byte의 serial number 1개 생성하여 hash값 뒤에 붙임으로 hash의 중복을 제거했습니다.
Exthash가 key 중복 사용 문제를 해결하는 원리
Exthash가 key 중복 사용 문제를 어떻게 해결할 수 있는지 간단한 예제를 통해 살펴보겠습니다. 널리 알려진 이더리움의 예제와 아래 계좌 정보를 이용해 MPT를 각각 hash와 Exthash의 형태로 표현해 보겠습니다.
a711355 : 45.0 KLAY
a77d337 : 1.00 ston
a7f9365 : 1.10 KLAY
a77d397 : 1.00 ston
우선 hash로 위 계좌 정보를 MPT로 표현해 보겠습니다. 보다시피 마지막 Leaf2가 동일한 정보를 갖고 있어 양쪽 노드에서 참조되는 문제가 있습니다.

이제 Exthash로 위 계좌 정보를 표현해 보겠습니다. 추가된 ExthashNonce는 편의상 붉은 색(예: xxx1, xxx2 )으로 표현을 했습니다. Exthash의 영향으로 Leaf3가 추가 되긴했지만 중복 참조되는 노드는 없음을 알 수 있습니다.

Exthash로 hash를 얻는 과정
이제 Exthash를 써서 기존의 root hash를 생성하는 과정을 단계별로 살펴보도록 하겠습니다. 앞에 나온 Diagram-1과 2는 hash 계산이 완료된 상태의 MPT 그림이며 hash가 계산되기 전 메모리상의 MPT 상태는 아래 Diagram-3로 표현해 보았습니다.

hash계산은 아래에서 부터 위로 이루어지기 때문에 Leaf3에서 시작됩니다.
- Leaf3는 Exthash가 존재하지 않음으로 그냥 hash를 계산하면 “5597…7d27”이 됩니다. 여기에 serial index “xxx1″을 붙이면 Leaf3의 Exthash 값은 “5597…7d27xxx1”이 됩니다.
- Leaf3에 연결된 Branch1의 9번 child를 “5597…7d27xxx1”으로 업데이트합니다.
- Leaf2도 Leaf3와 hash 계산값은 동일하지만 serial index는 “xxx2″가 되어 Leaf2의 Exthash 값은 “5597…7d27xxx2”가 됩니다.
- Branch1의 3번 child를 “5597…7d27xxx2”로 업데이트합니다.

5. 이제 Extension1의 hash를 계산할 차례입니다. Extension1에 연결된 Branch1에는 2개의 Exthash가 존재합니다. hash 계산을 위해 Exthash의 xxx1, xxx2를 잠시 제거하고 (“5597…7d27”, … , “5597…7d27”,…) hash를 계산하면 “127f…6d00″가 됩니다. 여기에 serial index “xxx3″을 붙입니다(“127f…6d00xxx3”).

6. Leaf1, Leaf0에는 Exthash가 없으므로 바로 hash를 계산할 수 있습니다. 계산값에 serial index인 xxx4, xxx5를 각각 붙입니다. (즉, Leaf1 – “6c8d…5660xxx4”, Leaf0 – “6c8d…5660xxx5”)
7. Extension1의 value(“127f…6d00xxx3”)는 Exthash의 형태이므로 이전과 마찬가지로 serial index를 제거하고 hash를 계산한 후 (“945e…f7af”) xxx6을 붙입니다( “945e…f7afxxx6”).
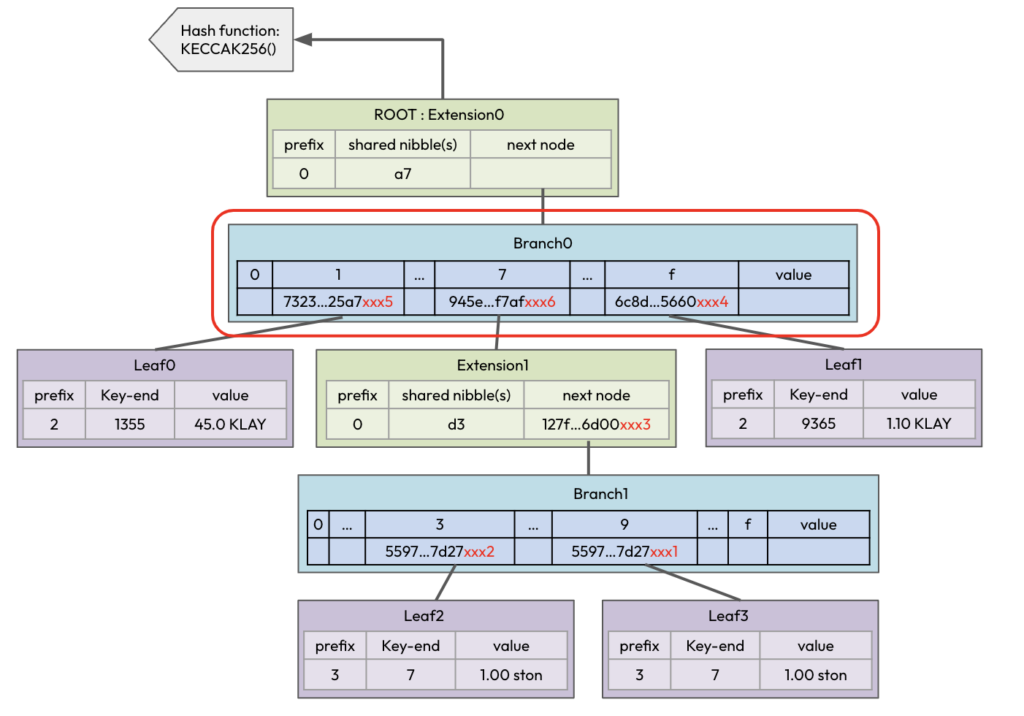
8. 마지막으로 Branch0과 Extension0에도 Branch1과 Extention1에서와 동일한 과정을 적용하면 Diagram-2와 같은 결과가 나오며 최종적으로 Diagram-1과 동일한 root hash를 얻게 되어 호환성이 유지 됩니다.
Exthash로 pruning하는 과정
이제는 노드를 삭제(pruning)과정을 설명해 보도록 하겠습니다.
hash로 pruning
먼저 hash로 구성된 MPT 노드를 삭제해 보겠습니다.
1. Diagram-1을 key : value 형식으로 표현하면 다음과 같습니다.
Extension0 - acec...e3c5 : [ "a7", "72fd...b753" ]
Branch0 - 72fd...b753 : [ 0:N, 1:"7323...25a7", 2:N, ..., 7:"945e...f7af", 8:N, ..., f:"6c8d...5660", val ]
Leaf0 - 7323...25a7 : [ "1355", 45.0 KLAY ]
Extension1 - 945e...f7af : [ "d3", "127f...6d00" ]
Leaf1 - 6c8d...5660 : [ "9365", 1.10 KLAY ]
Branch1 - 127f...6d00 : [ 0:N, ..., 3:"5597...7d27", ..., 9:"5597...7d27", ..., f:N, val ]
Leaf2 - 5597...7d27 : [ "7", 1.00 ston ]2. 만약 a77d397 account의 잔고가 1.00 ston에서 2.00 ston로 변경된다면 Diagram-1은 아래의 Diagram-7로 변합니다(연두색 배경의 노드가 새롭게 업데이트된 노드입니다).
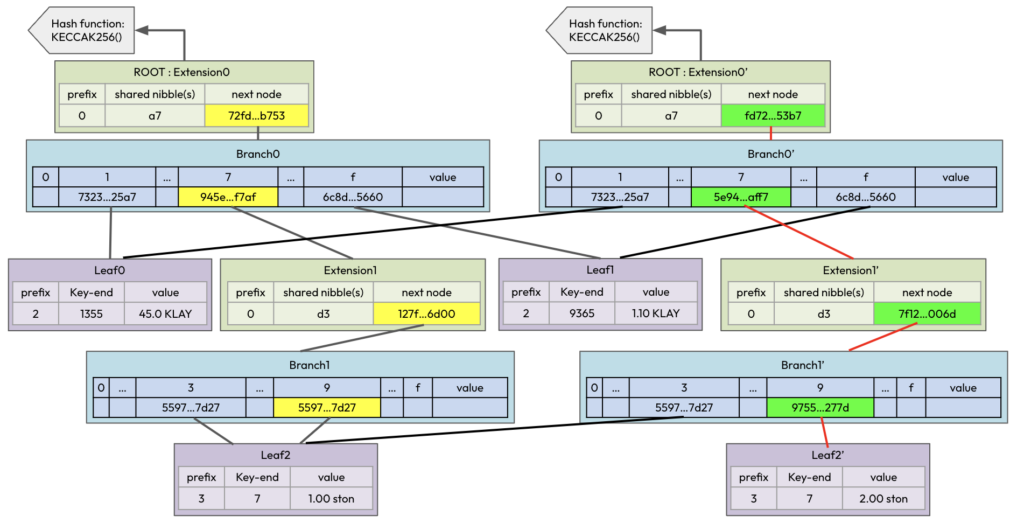
3. Diagram-7을 key : value형식으로 표현해 보겠습니다.
Extension0 - acec...e3c5 : [ "a7", "72fd...b753" ]
Branch0 - 72fd...b753 : [ 0:N, 1:"7323...25a7", 2:N, ..., 7:"945e...f7af", 8:N, ..., f:"6c8d...5660", val ]
Leaf0 - 7323...25a7 : [ "1355", 45.0 KLAY ]
Extension1 - 945e...f7af : [ "d3", "127f...6d00" ]
Leaf1 - 6c8d...5660 : [ "9365", 1.10 KLAY ]
Branch1 - 127f...6d00 : [ 0:N, ..., 3:"5597...7d27", ..., 9:"5597...7d27", ..., f:N, val ]
Leaf2 - 5597...7d27 : [ "7", 1.00 ston ]
Leaf2' - REDD...7d27 : [ "7", 2.00 ston ]
Branch1' - REDD...6d00 : [ 0:N, ..., 3:"5597...7d27", ..., 9:"9755...277d", ..., f:N, val ]
Extension1'- REDD...f7af : [ "d3", "7f12...006d" ]
Branch0' - REDD...b753 : [ 0:N, 1:"7323...25a7", 2:N, ..., 7:"5e94...aff7", 8:N, ..., f:"6c8d...5660", val ]
Extension0'- REDD...e3c5 : [ "a7", "fd72...53b7" ]4. pruning의 관점에서 보면 프라임(‘) 기호가 붙은 노드들(예: Leaf2′, Branch1’, …)은 업데이트된 노드이기 때문에 업데이트 전의 노드를 삭제할 필요가 있습니다. 그런데 Leaf2’의 원본노드인 Leaf2를 지우면 데이터가 유실됩니다. 왜냐하면 Branch1에서 Leaf2를 중복으로 참조하고 있었기 때문입니다. 지금은 예제이기 때문에 간단히 표현되었지만, 수십억 노드로 연결되어 있는 MPT에서는 어떤 노드가 새롭게 업데이트 되었을때 지울 수 있는 과거의 노드가 무엇인지 판단할 수가 없습니다. 따라서 live puning을 진행할 수 없습니다.
Exthash로 pruning
이제 Exthash로 구성된 MPT 노드를 삭제해 보도록 하겠습니다.
1. Diagram-2를 key : value 형식으로 표현하면 다음과 같습니다.
Extension0 - acec...e3c5 : [ "a7", "72fd...b753xxx1" ]
Branch0 - 72fd...b753xxx7 : [ 0:N, 1:"7323...25a7xxx2", 2:N, ..., 7:"945e...f7afxxx3", 8:N, ..., f:"6c8d...5660xxx4", val ]
Leaf0 - 7323...25a7xxx5 : [ "1355", 45.0 KLAY ]
Extension1 - 945e...f7afxxx6 : [ "d3", "127f...6d00xxx5" ]
Leaf1 - 6c8d...5660xxx4 : [ "9365", 1.10 KLAY ]
Branch1 - 127f...6d00xxx3 : [ 0:N, ..., 3:"5597...7d27xxx6", ..., 9:"5597...7d27xxx7", ..., f:N, val ]
Leaf2 - 5597...7d27xxx2 : [ "7", 1.00 ston ]
Leaf3 - 5597...7d27xxx1 : [ "7", 1.00 ston ]2. a77d397 account의 잔고가 1.00 ston에서 2.00 ston로 변경된다면 Diagram-2는 아래의 Diagram-8처럼 변합니다. a77d397에 관련된 Exthash는 모두 새로 계산되어 연두색 박스로 표현됩니다.
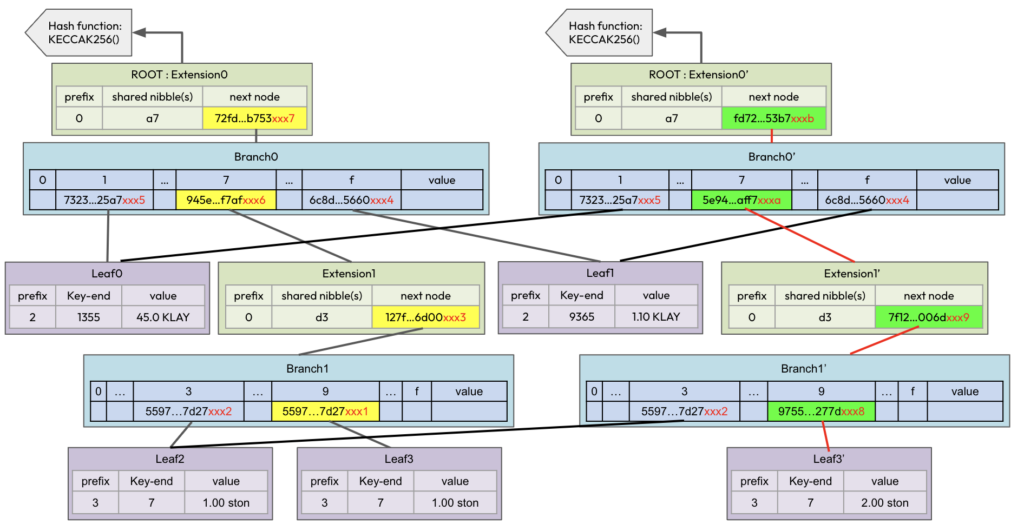
3. Diagram-8을 key : value형식으로 표현해 보겠습니다.
Extension0 - acec...e3c5 : [ "a7", "72fd...b753xxx1" ]
Branch0 - 72fd...b753xxx7 : [ 0:N, 1:"7323...25a7xxx2", 2:N, ..., 7:"945e...f7afxxx3", 8:N, ..., f:"6c8d...5660xxx4", val ]
Leaf0 - 7323...25a7xxx5 : [ "1355", 45.0 KLAY ]
Extension1 - 945e...f7afxxx6 : [ "d3", "127f...6d00xxx5" ]
Leaf1 - 6c8d...5660xxx4 : [ "9365", 1.10 KLAY ]
Branch1 - 127f...6d00xxx3 : [ 0:N, ..., 3:"5597...7d27xxx6", ..., 9:"5597...7d27xxx7", ..., f:N, val ]
Leaf2 - 5597...7d27xxx2 : [ "7", 1.00 ston ]
Leaf3 - 5597...7d27xxx1 : [ "7", 1.00 ston ]
Leaf3' - 9755...277dxxx8 : [ "7", 2.00 ston ]
Branch1' - 7f12...006dxxx9 : [ 0:N, ..., 3:"5597...7d27xxx2", ..., 9:"9755...277dxxx8", ..., f:N, val ]
Extension1'- 5e94...aff7xxxa : [ "d3", "7f12...006dxxx9" ]
Branch0' - fd72...53b7xxxb : [ 0:N, 1:"7323...25a7xxx5", 2:N, ..., 7:"5e94...aff7xxxa", 8:N, ..., f:"6c8d...5660xxx4", val ]
Extension0'- ecac...c5e3 : [ "a7", "fd72...53b7xxxb" ]4. Leaf3의 Balance가 변경됨에 따라 Leaf3, Branch1, Extention1, Branch0, Extension0가 각각 Leaf3′, Branch1′ Extention1′, Branch0′, Extension0’으로 업데이트되었습니다. 그리고 최신 데이터 이외에 과거 노드인 Leaf3, Branch1, Extention1, Branch0, Extension0를 삭제할 수 있습니다. 왜냐하면 추가된 7바이트로 인해 중복 참조하는 노드가 존재할 수 없기 때문입니다. 따라서 “5597…7d27xxx1”, “127f…6d00xxx3”, “945e…f7afxxx6”, “72fd…b753xxx7”, “acec…e3c5″가 모두 삭제되고 live pruning이 완료됩니다.
StateDB Live Pruning이 노드에 미치는 영향
StateDB Pruning을 하게 되면 최근 이틀 동안의 상태 데이터(기본 172,800 블럭)만 state trie에 남게 되고, 그 이전 상태 데이터의 key-value는 삭제 됩니다. 그 결과로 StateDB의 용량은 150 ~ 200GB 정도의 비교적 작은 크기로 유지됩니다. 이로 인해 스토리지 관련 캐시의 hit ratio가 증가해서 IO 성능 또한 개선됩니다.
과거 데이터를 삭제해야 하기 때문에 delete queue가 추가 되고 실제로 key-value를 삭제하는 과정이 추가되어 시스템 부하가 증가될 수 있지만, 실제 시스템 모니터링 결과 결과적으로 증가하는 부하량은 없는 것으로 확인되었습니다. (개선된 IO 성능으로 상쇄된 것으로 추정)
StateDB Live Pruning 기능을 활성화해 노드 실행하기
StateDB Pruning에서는 Exthash라는 새로운 타입을 사용하기 때문에 기존의 archive sync, full sync의 방법으로만 DB 마이그레이션의 수행할 수 있습니다. 하지만 DB의 용량 자체가 많이 줄어들기 때문에 다운로드 받아서 싱크를 맞추는데 큰 부담이 없습니다. 실제 snap sync나 fast sync 기능을 이용할 때 다운 받을 데이터 사이즈와 StateDB Pruning된 DB의 용량적 차이는 미미 합니다. 이 문서를 참고하여 StateDB Live Pruning 기능을 활성화하실 수 있습니다.
StateDB Live Pruning의 향후 발전 방향
StateDB Live Pruning기능에 적합한 노드는 CN(consensus node)과 PN(proxy node) 노드입니다. 이 두 개의 노드 타입은 최신 데이터로 싱크를 맞추고 validate하는게 주요 기능이기 때문에 과거 데이터를 지우는 StateDB Live Pruning 기능을 적용하기에 가장 적합한 노드 타입 입니다.
하지만 EN(endpoint node) 노드처럼 다양한 API요청을 처리해야 하는 노드에는 StateDB Live Pruning 기능이 적합하지 않을 수 있습니다. 그래서 과거 데이터를 지우는 대신에 다른 스토리지로 옮기는 StateDB 마이그레이션 기능을 고려하고 있습니다. 최신 상태 데이터는 핫 스토리지(성능 좋고 용량이 적은)에 저장하고, 과거 데이터는 콜드 스토리지(용량이 크고 조금 느린)에 저장해서 스토리지의 비용효율을 개선시키려 합니다.
또한 header, body, receipt 등의 정보를 추가로 삭제할 수 있는 옵션을 제공하여 노드를 더 가볍게 운영할 수 있도록 할 예정입니다.