
블록체인 플랫폼마다 추천하는 하드웨어 스펙이 있고 이를 그대로 따르는 블록체인 노드 운영자가 있을 수 있습니다. 하지만 실제 노드 운영을 해보면 자본이 한정적이거나 추천 스펙이 본인이 필요로 하는 스펙과 정확히 일치하지 않을 수 있습니다. 이 때 본인의 노드에 더 필요한 자원과 덜 필요한 자원이 무엇인지 스스로 파악할 수 있다면, 추천 하드웨어 스펙을 베이스라인으로 해서 최적의 하드웨어 조합을 찾아 성능 대비 비용 측면에서 효율적인 노드 운영을 할 수 있습니다.
이번 포스팅에서는 Klaytn 노드의 하드웨어 스펙을 결정하는 실험 중 하나를 정리하여 공유함으로써 블록체인 노드 운영자들이 하드웨어 스펙을 결정할 때 참고할 수 있는 정보를 제공하고자 합니다.
나아가, Klaytn 노드 운영을 위한 추천 하드웨어 스펙이 업데이트되었습니다. 이전에는 Klaytn 메인넷 출범 당시의 스펙이었지만, 지금은 CPU 성능 등의 인프라가 발전하고 현재 메인넷에 쌓인 데이터 양이 많아져서 이를 고려한 실험 결과를 바탕으로 새로운 추천 하드웨어 스펙이 도출되었습니다. 따라서, 비용과 성능 측면에서 새로운 추천 스펙을 사용하는 것을 권장합니다. 한편, 추천 스펙은 레퍼런스로만 활용하여, 각 노드의 상황에 맞게 최적의 노드 스펙을 선택하는 것이 바람직합니다.
노드 운영 시 알고 있어야 할 기본적인 사항들
저장 장치
IOPS가 높을수록 시간당 처리할 수 있는 I/O 작업 개수가 많아집니다. 따라서 이러한 값들이 높은 스토리지 일수록 값을 읽고 쓸 때 속도가 빨라지는데요, 따라서 블록체인에 데이터가 많이 쌓여있을수록 블록 생성 및 블록 처리시 이 값의 영향을 크게 받습니다. 그 이유는 DB 캐시의 크기가 일정한 상황에서 데이터가 많을수록 DB 캐시에서 읽어오는 비율이 낮고 Cache Miss가 많아 I/O 처리량이 많아지기 때문입니다.
메모리
또 다른 측면에서 생각해보면, 같은 크기의 데이터와 동일한 스토리지 성능을 가지고 있는 두 노드라도 메모리 크기에 따라 성능 차이가 많이 날 수 있습니다. 어찌보면 당연하다고 할 수 있는데요, 메모리가 크다면 DB 캐시 크기를 더 많이 줄 수 있어 I/O 처리량이 감소하기 때문입니다. 하지만 무작정 메모리 크기를 늘린다고 해서 성능이 비례해서 올라가지는 않는데요, 어느 수준 이상의 크기를 갖춘 이후로는 메모리 크기 증가로 인한 성능 향상의 효율이 낮아집니다.
*Protip. 클레이튼 코드를 보면 이러한 Cache miss와 관련된 지표를 제공하고 있는데요, klaytn_trie_memcache_clean_miss 지표를 살펴보는것도 도움이 될 것 같습니다.
CPU
트랜잭션 풀에서 많은 트랜잭션들을 관리하거나 많은 블록을 싱크하는 등 동시에 처리해야할 작업이 많기 때문에 병렬 처리가 도움이 되는 측면이 있긴 하나, 가장 중요한 최신 블록이 처리되는 경로는 단일 스레드로 작업 되기 때문에 코어 하나의 성능이 전체 성능에 많은 영향을 끼칩니다.
CPU 벤치마크 및 가격
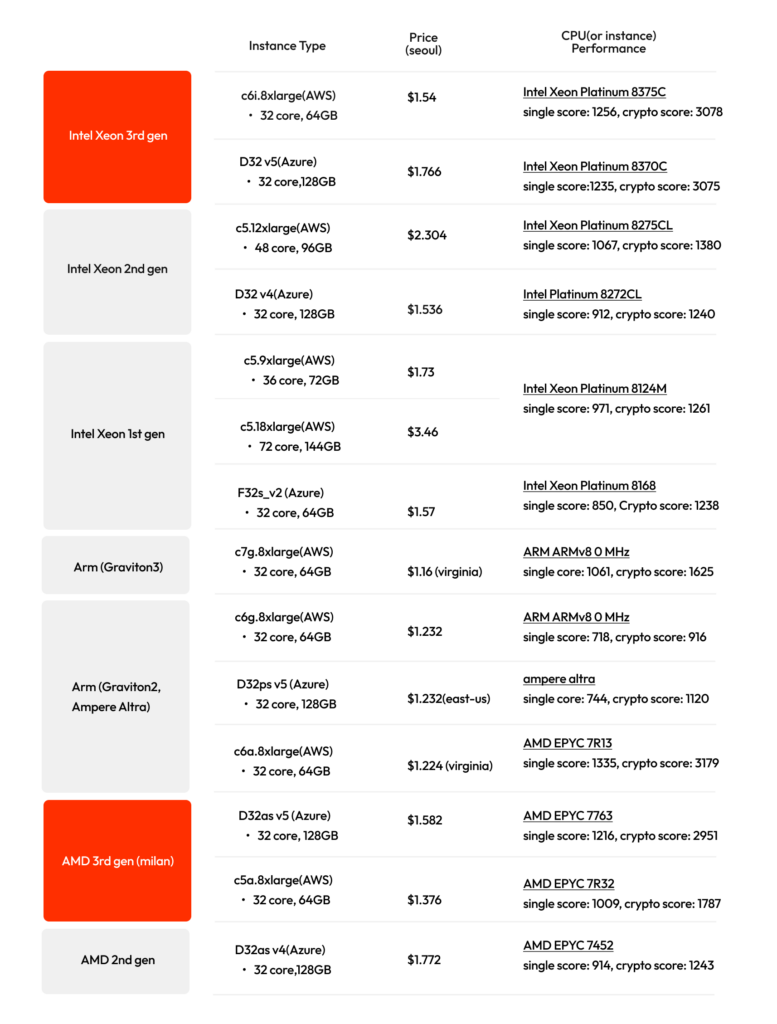
AWS, Azure 와 같은 대중적인 클라우드 서비스에서 제공중인 EC2 서비스들의 CPU 들의 가격과 벤치마크 결과는 다음과 같습니다. Intel과 AMD의 경우 최신세대의 CPU들이 그 이전 세대의 CPU들보다 crypto 성능이 두세배 이상 상승하였고 종합 성능인 single score 역시 20~30% 상승하였습니다.
한편, 클라우드 서비스들이 책정한 가격을 보면 이전 세대와 가격 차이가 크게 나지 않았습니다. 따라서 아래 표에서 노란색으로 마크된 최신 세대의 CPU들이 제일 가격측면에서 효율적이라고 판단됩니다.
실험 및 결과
그렇다면, 실험은 어떻게 구성하고 실행했을까요? 실험 이야기를 하기 위해, 먼저 Klaytn 네트워크를 간략하게 살펴보겠습니다. Klaytn에는 세가지 타입의 노드가 있습니다.
- EN(endpoint node)
- PN(proxy node)
- CN(consensus node)
EN은 rpc가 오픈되어 있어 public 으로부터 트랜잭션을 받아들이고 처리할 때 사용하는 노드입니다. 이 때 블록에 포함될 필요가 있는 트랜잭션들은 부트 노드를 통해 연결된 PN에게 전달됩니다. PN은 불특정다수에게 들어오는 트랜잭션들을 받아주는 역할을 하고, 결국 이 트랜잭션들은 블록을 생성하는 역할을 맡고 있는 CN들에게 전달되어 블록 안에 포함되게 됩니다.
실험은 클레이튼 클라이언트를 이용한 별도의 프라이빗 네트워크 상에서 수행되었고, 4개의 CN, 8개의 PN, 4개의 EN으로 네트워크를 구성하여 CN의 cpu / memory / storage 스펙을 변경해가며 수행하였습니다. 그 결과로는 초당 트랜잭션 처리 속도인 TPS 값이 높을수록 좋은 스펙이다라고 판단하였습니다. 그 외에 OOM(out-of-memory) 등 안정성 측면에서 문제가 없는지 살펴보았습니다.
부하와 관련된 조건은 다음과 같이 설정하였습니다.
- 6000 RPS(requests-per-second): 초당 6000개의 트랜잭션을 발행하는 부하를 주도록 하였습니다. 네트워크 최대 처리량을 확인하기 위해 예상 처리량 이상의 과부하 상황을 유도하기 위함입니다. 이때의 테스트 트랜잭션은 sender 계정에서 receiver 계정으로 KLAY를 단순 전송하는 내용입니다.
- 총 5000만 계정, 500만 활성 계정: 실제로 클레이튼 메인넷엔 대략 3000만 개의 EOA가 존재한다고 분석되는데요, 앞으로 더 증가될 것을 감안하여 5000만 정도를 테스트 계정 수로 설정하였습니다. 그리고 이 계정들에 미리 KLAY를 채워넣었으며 이를 통해 DB 상에 5000만 어카운트가 생성되어 DB 크기가 그만큼 커지게 되어 DB read 속도가 떨어지게 됩니다. 이 중 실제로 테스트 트랜잭션을 발행할 땐 이 중 10%의 계정만이 활성화되어 테스트에서 활용되는데, 이는 실제 메인넷의 활성화된 계정 개수를 참조한 값입니다.
위 조건하에 설정한 두 종류의 실험과 그 결과를 소개하겠습니다. 첫번째로는 AWS EC2의 여러 타입을 픽해 CN으로 띄운 후, TPS가 어떻게 나오는지 살펴보았습니다. 참고로, c5 타입은 Intel Xeon 2세대 CPU를 사용하지만 비교군으로 함께 실험해보았습니다.
Test 1
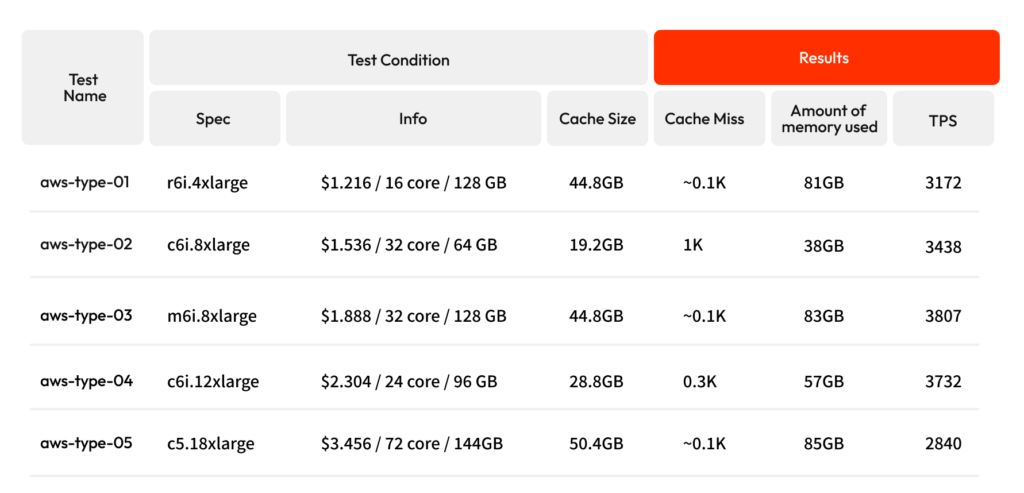
- Cache Size: 여기서 말하는 캐시란 StateDB의 캐시를 말하는 것으로, DB보다 빠른 접근속도를 위해 최근에 읽고 쓴 State 값들을 메모리상에 복사해놓은 것을 State Cache라고 함. 기본적으로 전체 물리메모리 크기의 30~40%가 할당이 되는데 `–state.tries-in-memory` flag를 통해 임의로도 지정할 수 있음.
- Cache Miss: 캐시에 읽고자 하는 값이 없는경우 Cache miss가 났다고 하는데, 이러한 경우 DB에서 해당 값을 직접 읽어와야 하는 i/o 작업이 필요하기 때문에 캐시에서 바로 읽어가는 것보다 속도가 느림.
- Amount of memory used: 메모리가 계속 증가하다가 일정 크기 이상이 되면 메모리 크기가 안정화되는 구간이 시작되는데, 이 때의 메모리 크기를 말함.
주요한 결론으로 m6i.8xlarge 정도 되어야 4000 TPS에 가까운 성능이 나온다는 것을 알 수 있었습니다. 그 밖에 도출된 결과는 다음과 같습니다.
- ~0.1K 이하의 Cache Miss가 나면 미스율이 최저라고 할 수 있는데, 메모리 크기가 최소 100기가 이상은 되야 최저로 나올 수 있었습니다.
- r6i.4xlarge와 c6i.8xlarge를 보면, 코어수와 메모리 크기가 서로 반대로 설정되어 있는데, 메모리크기가 r6i가 두 배 이상이라 캐시 미스는 거의 없으나 코어 수가 절반이라 TPS 성능이 떨어진 것을 볼 수 있습니다.
- 특히 c5.18xlarge를 보면 메모리 / 코어 개수도 제일 크나 결정적으로 싱글 코어의 성능이 떨어지기 때문에 성능이 제일 낮은 것을 볼 수 있습니다.
Test 2
다음은 state db의 캐시 크기를 달리해보며 OOM 이 발생되는지 보기 위한 실험입니다. 캐시 크기는 –state.tries-in-memory flag를 통해 매뉴얼하게 설정 가능합니다.
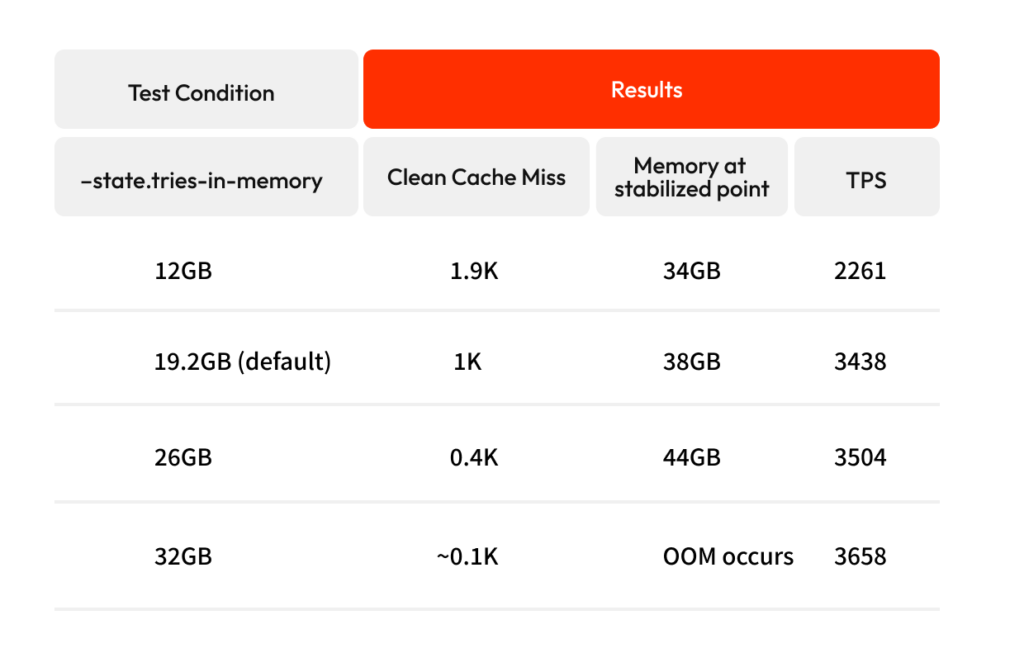
- 테스트에 사용된 EC2: c6i.8xlarge(32 core, 64GB)
- EN에서 추천하는 메모리 크기인 64GB 선택
- 이 중 메모리 크기 대비 코어 수가 제일 많은 타입인 c6i 사용
캐시 크기를 계속 증가시키다 보면 어느 순간 필요로 하는 메모리 크기가 전체 물리 메모리 크기를 초과하게 되어 OOM이 발생된 것을 볼 수 있습니다. 따라서 캐시로 설정한 크기보다 20GB(30%) 이상 여유를 둬야 다른 기능들이 사용하는 메모리까지 충분히 감당할 수 있기 때문에 OOM을 방지할 수 있다는 것을 알 수 있습니다.
추가적으로 스토리지 측면에서도 테스트를 해보았는데요, 위에서 언급한 바와 같이 IOPS가 더 높을수록 더 높은 성능을 보였습니다.
추천 스펙
위의 내용을 종합하여, Klaytn 팀이 추천하는 클라우드 환경별 스펙은 다음과 같습니다. 해당 정보는 KlaytnDocs에서도 확인하실 수 있습니다.
Recommend spec
- CN: aws – m6i.8xlarge, azure – D32s v5 (32 core or more, 100GB or more)
- PN: aws – m6i.4xlarge, azure – D16s v5 (16 core or more, 60GB or more)
- EN: aws – r6i.2xlarge, azure – E8 v5 (8 core or more, 60GB or more)
Storage
- Please set it as high as you can. Ex. gp3, 16,000 IOPS, 500 MiB/s of throughput
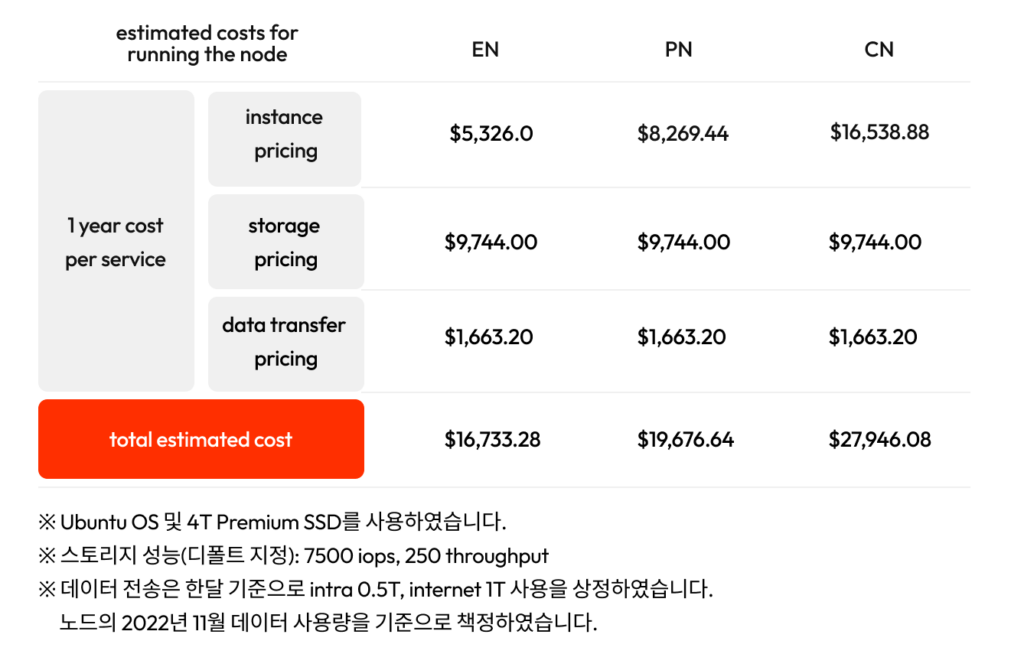
추천하는 클라우드 환경별 스펙에 따른 1년치 예상 운영 비용은 다음과 같습니다. 기존 추천 스펙으로 CCO를 돌리는 것에 비해 새로운 스펙으로 돌릴 경우 약 30% 정도 비용이 절감될 수 있습니다.
AWS, Seoul Region
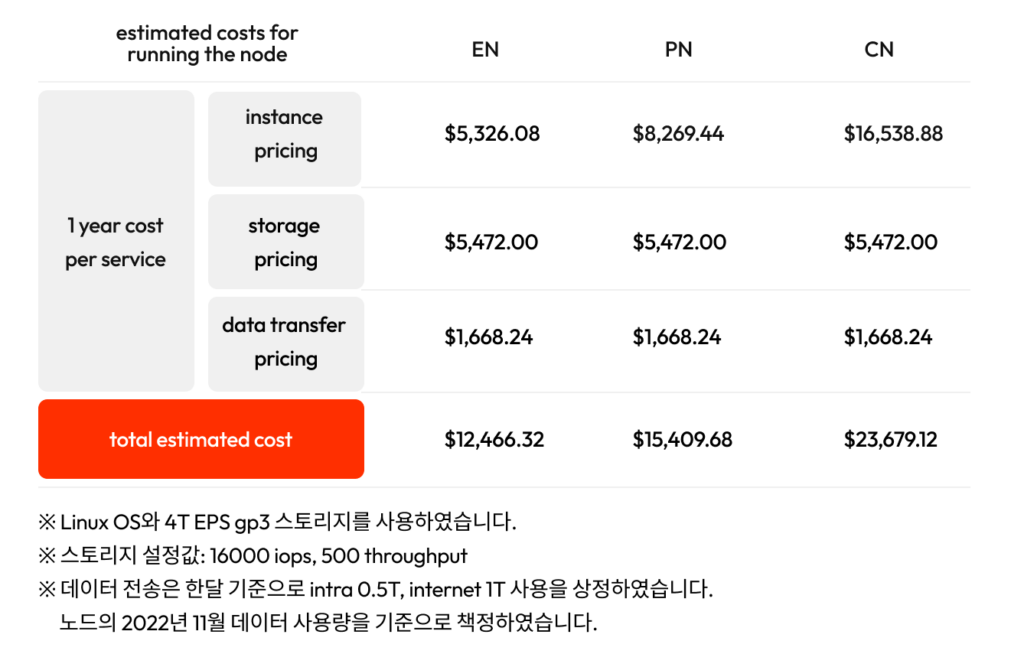
Azure, Korea Central Region
한편, 본인이 노드를 어떻게 사용하는지에 따라 최적의 스펙은 충분히 달라질 수 있기 때문에, 추천 스펙을 바탕으로 노드 스펙을 정하는 것이 바람직합니다.
상황에 따른 추천 스펙
- CN/PN의 경우, state migration 을 수행하기 위해서는 많은 메모리 필요합니다. cloud 환경인 경우 migration 수행할 때는 메모리 크기를 증가시키는 것을 권장하며, chaindata-migration 참고하시길 바랍니다.
- EN의 경우 HTTP/WS 서버를 통해 연결된 사용자 수나 요청된 API에 따라 더 높은 cpu/memory를 요구할 수 있습니다.
블록체인 노드 운영자들에게 있어서 운영비는 모두 풀기 어려운 문제라고 생각합니다. 해당 내용을 통해 비용을 절감할 수 있는 방법에 대한 힌트를 얻으셨기를 바랍니다.